In fact, it is hard to find in English grammar
an external similarity like we see at these two too different, at
least for the surface impression, words: mean, name.
First of all, they have the same letters:
name
= mean (1)
Second
and more serious one, meaning and naming both are external
descriptions of an internal being. We say: “he has a name for
being honest”, by this phrase we mean when we pronounce his
name our association shifts to a honesty and vice versa, when we talk
about a honesty our association shifts to some persons who are the
representative for this concept. In other words, a
name is the replacement of a phrase describing a person or a thing,
or, in order to achieve a definition of somewhat
new and meaningful we give it a new name (by names we mean
here words which could not be met in a regular dictionary, e.g.
George Bush, Coca-Cola, Nokia, Sun, Java, J2EE, Microsoft, .NET,
Google, Yahoo!, Z-machine etc.).
In the web more
than 95% of words are names and most of them are unique names, for
example almost all trade marks. Currently, we can answer a popular
question in
NLP (Natural Language Processing), how can we operate in artificial
intelligence like human? In other words, how
can we shift our emphasis from textual elements to their meanings?
At
the web it is very simple, we just should deal with names, which are
meanings them-selves.
|
|
In our reality when we look for
information in any search system, and give as a search request a
unique name, we almost always succeed to find a relevant result
relatively fast. This fact stems from the relationship between
names and their meanings, as was mentioned above. Remains the
only question: how can we use this relationship in an automatic
search system?
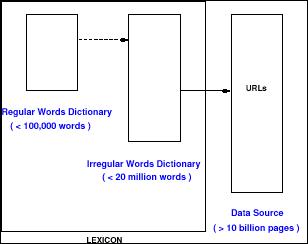
In
a search engine a lexicon is one of the essential parts, it
weaves words and phrases
with their sources (web pages). By today it was built logically
as 2-tier technology, where the first tier contains words or
phrases and the second one contains words' sources. Our
proposition is shifting a lexicon from 2-tier to 3-tier
technology. In other words, it is a separating of a lexicon into
2 dictionaries, where the first one contains regular words (e.g.
table, computer, book, disk etc.), the second one contains
irregular words (names, e.g. Coca-Cola), and only as a
third tier we propose an information source, such as Web URLs.
|
Irregular
words dictionary or a names dictionary can be separated into a few
popular topics; e.g. Persons, Organizations, Science,
Art, Products, Phone Numbers, E-mails and
Miscellaneous.
A
non-trivial question remains here, it is a relationship between words
and names, we call this as a soft relationship, while the
relationship between names and data sources we call as a strong
relationship.
For
overcoming this non-triviality we should involve here a human
community formed by subjects who are, at the same time, users and
information providers. Those community subjects should
only check and alter the word-to-name relationships prepared by
artificial tools.
©
UnChaos Ltd.